AtCoder Heuristic Contest 053: Random Sum Game
Table of Contents
1. Intro
A few weeks ago I participated in AtCoder Heuristic Contest 053, a 4-hour optimization challenge where you’re tasked with finding the best solution to an open-ended problem. Out of 1069 participants who submitted code, I placed 153rd. This post is a walkthrough and reflection on my approach to the competition.
2. The Problem
The problem is a two-phase card game where you must group cards to sum to specific target values.
Phase 1: Value Selection We’re given 500 blank cards and must assign each a value between 1 and 10¹⁵.
Phase 2: Assignment Phase After Phase 1, we’ve committed to our 500 card values. The system then:
- Generates 50 random “target” numbers, each in the range [9.98 × 10¹⁴, 1.002 × 10¹⁵]
- We must group our 500 cards into 50 piles (one per target)
- Each card can be used at most once or discarded
- Piles can be empty
- Goal: make each pile’s sum as close as possible to its target
Scoring is based on the sum of absolute differences between each pile’s sum and its target.
Example (simplified scale):
Phase 1:
We assign our 10 cards values:
[200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100]
Phase 2:
Given random targets:
[1800, 2100, 2400]
We assign:
- Pile 1 (target 1800):
[1100, 700] → sum = 1800 (error: 0)
- Pile 2 (target 2100):
[1000, 900, 200] → sum = 2100 (error: 0)
- Pile 3 (target 2400):
[800, 600, 500, 400] → sum = 2300 (error: 100)
Unused cards: [300]
Total error: 0 + 0 + 100 = 100
3. Walkthrough
I’ll walk through my approach during the competition in chronological order.
3.1. First trivial implementation
AtCoder provides input via STDIN and reads output from STDOUT. I implemented a trivial solution to verify I/O was working correctly: assign card values 1 through 500, then discard them all.
I also established a simple workflow for running my code locally and submitting it to the AtCoder visualiser:
./run-sample.sh > /tmp/output.txt && cat /tmp/output.txt | clip.exe
run-sample.sh runs my code and pipes an example input file (provided by AtCoder) into STDIN. The output is saved to a file and copied to the clipboard for easy pasting into the AtCoder visualiser tool. STDERR passes through to the terminal for debugging.
I’ll provide scores after each submission to show progress. There’s a formula for calculating the score based on the total error across 150 test cases, but it’s not important to understand the details. All you need to know is that higher is better.
Score: 24.8M1
3.2. First “real” submission
Next I implemented a “real” strategy. First, let me define some constants I’ll reference throughout this walkthrough:
LOWER= 9.98 × 10¹⁴ = 5 quadrillion - 2 trillion (minimum possible target value)UPPER= 1.002 × 10¹⁵ = 5 quadrillion + 2 trillion (maximum possible target value)RANGE=UPPER-LOWER= 4 × 10¹² = 4 trillion (span of possible target values)
The key insight: RANGE is tiny compared to the target values themselves. This means if we give each pile a base card worth LOWER, we’re already more than 99% of the way to any target before even starting.
After placing these base cards, we have 450 remaining cards, and each pile will need anywhere between 0 and RANGE additional value to reach its specific target.
Based on this insight, my strategy was:
- In Phase 1, generate 50 cards with value
LOWER. - For the remaining 450 cards, generate values between 0 and
RANGEusing a logarithmic distribution (heavily favoring smaller values). - In Phase 2, assign one of the
LOWERvalued cards to each pile. - For the remaining cards, loop through each one, assign it to whichever pile would get closest to that pile’s target without overshooting.
Score: 48.4M
3.3. Linear distribution and largest-first assignment
This initial approach improved my score significantly, but it was hard to get an understanding of how well it was working. I added some visualisations to show the selected card values, the used values and the discarded values.
These aren’t the prettiest visualisations, but here’s how to interpret them: Each image is a histogram with smaller values at the top and larger ones at the bottom. The Start and End columns show the boundaries of each bucket. The horizontal bars show the Count (number of values in each bucket). The Size column shows the range each bucket covers and isn’t particularly useful.
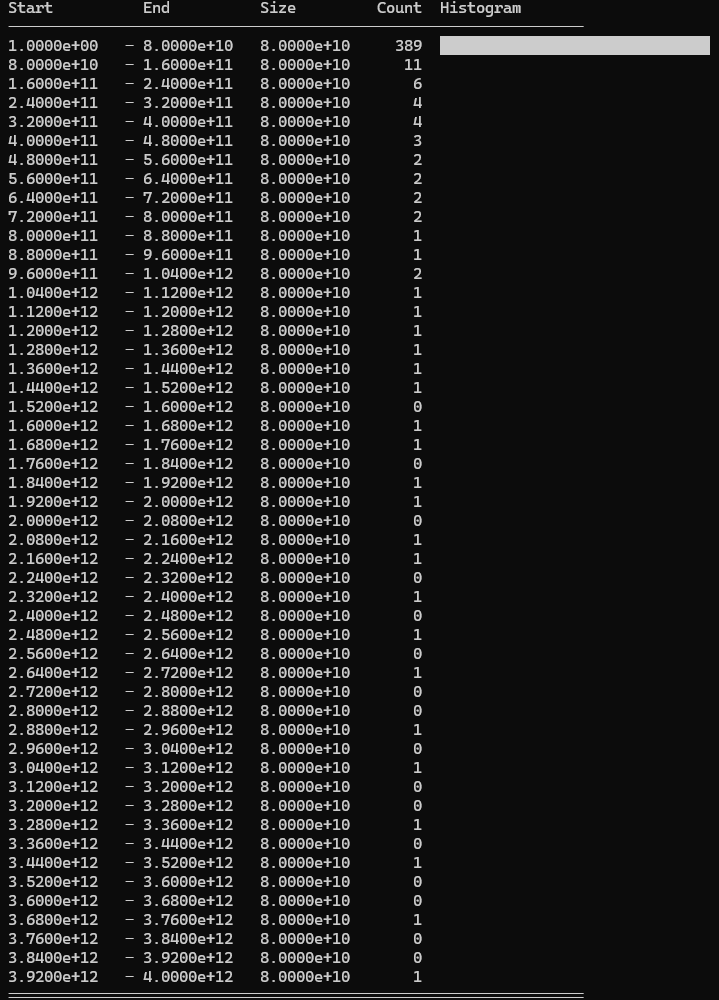
Selected values (excluding 50 hardcoded values): Logarithmic distribution heavily weighted to lower end.
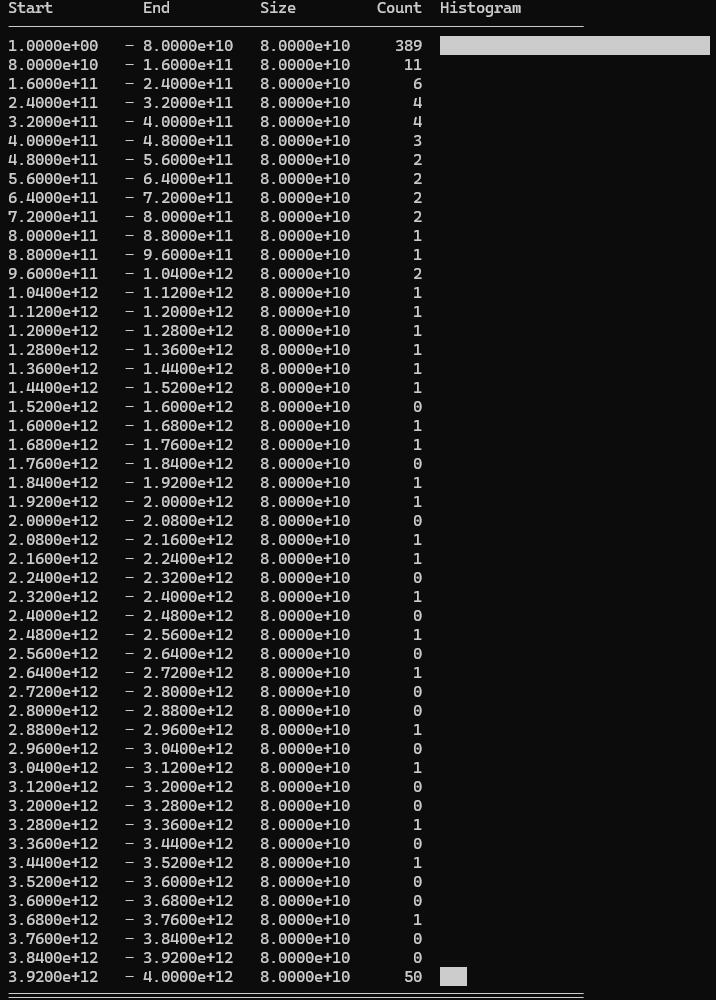
Used values: 499/500 cards used.
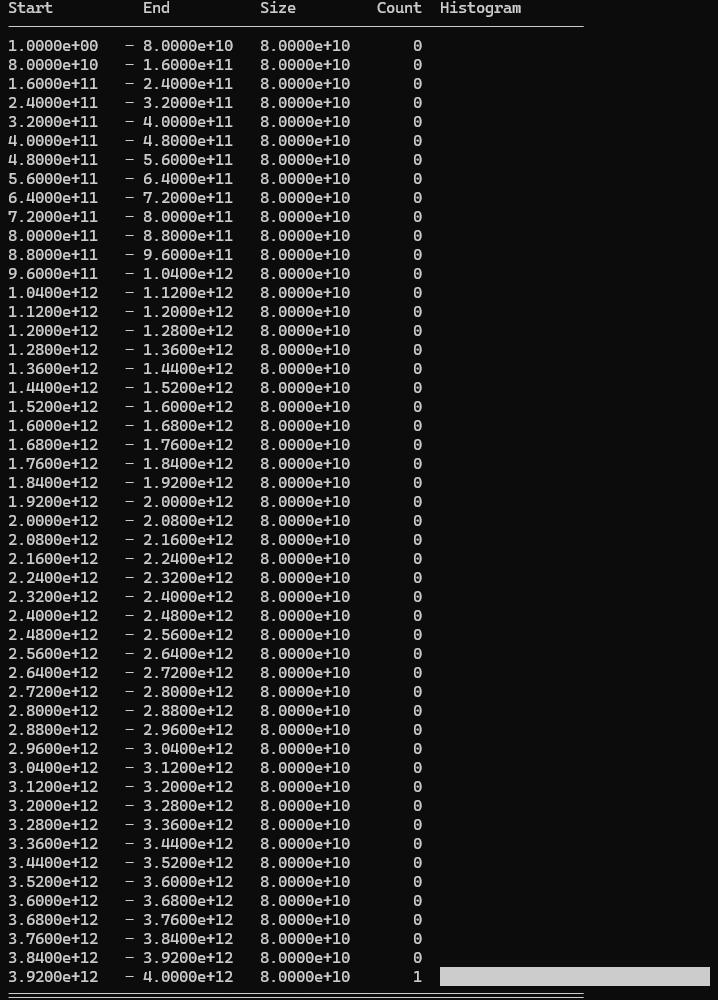
Discarded values: 1/500 cards discarded.
We can see the logarithmic distribution is very heavily skewed to the lower end of the range. On the bright side, only 1 card is discarded.
I decided to switch to a simple linear function for generating the card values, until I could come up with a more easily tweakable solution.
I also improved the Assignment Phase by modifying the greedy assignment approach to assign the cards in order from largest to smallest. The idea was to prioritise larger cards as they are harder to fit in later.
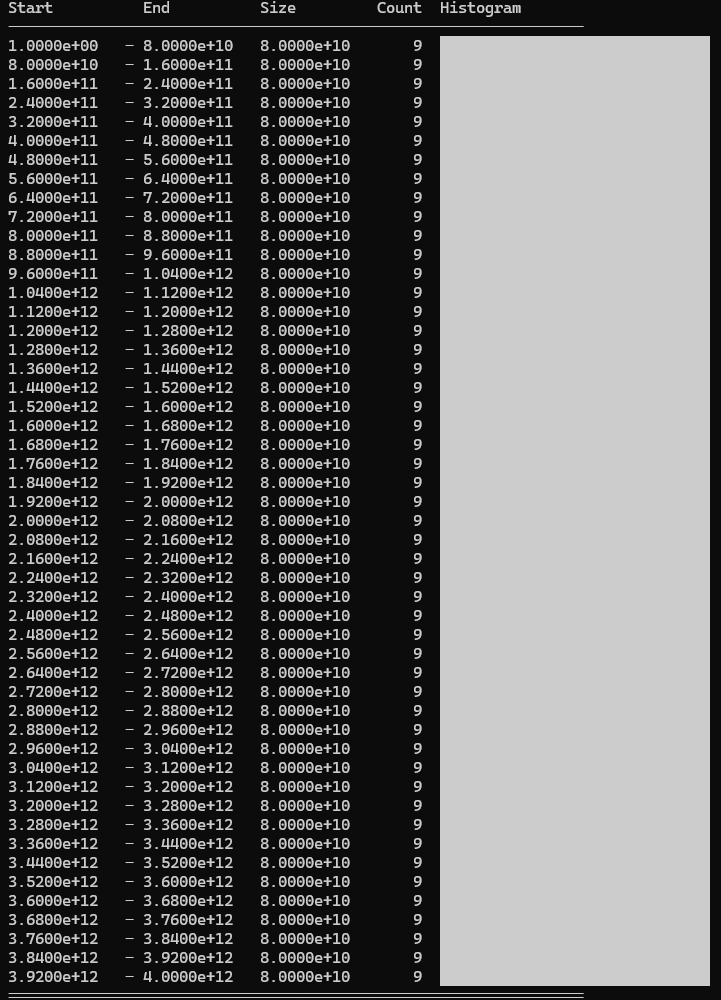
Selected values (excluding 50 hardcoded values): Linear distribution
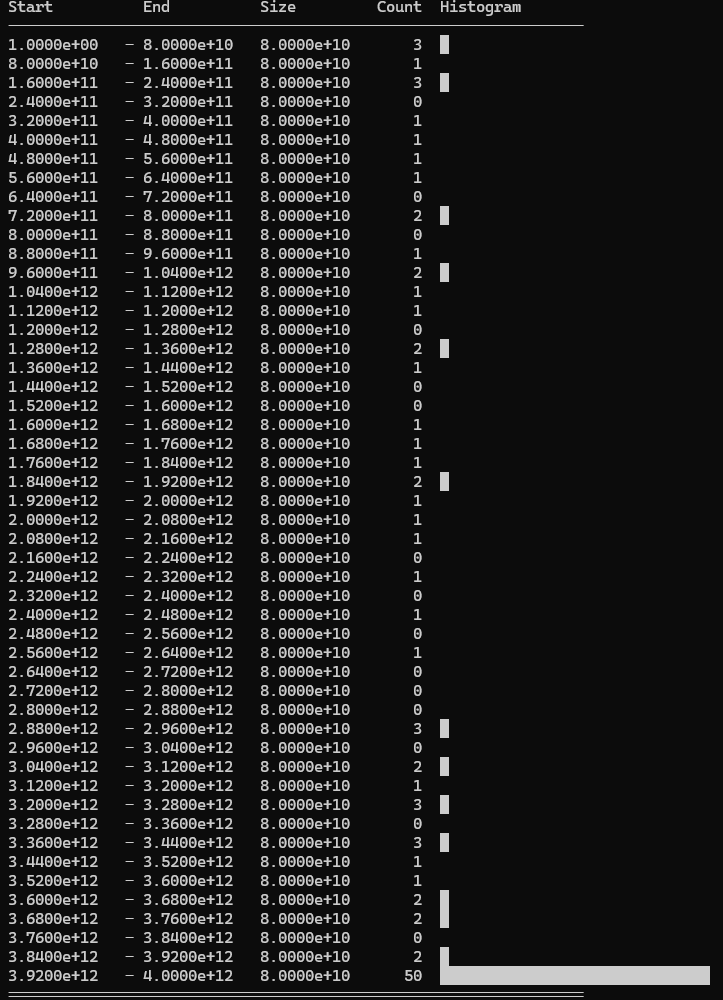
Used values: 102/500 cards used.

Discarded values: 398/500 cards discarded.
Most of the cards are now discarded, but this is still performing better than the previous solution.
Score: 64.7M
3.4. Parameterized exponential distributions
Next, I revisited the card generation. Intuitively, I felt having more cards with lower values and fewer cards with higher values would work better. I used an exponential function to generate cards between 0 and RANGE. This function has a k parameter which controls the shape.
I got Claude to generate an interactive html file so I could visualise card value distribution:
Exponential Function Visualizer
I also added a parameter to shrink the range by some shrink_factor. The idea here was that values close to 0 don’t make much difference, while values close to RANGE are too large to fit with other cards without overshooting. Shrinking the range excludes these less useful values.
Score: 60.8M (it went down, but I hadn’t tuned k and shrink_factor yet)
3.5. Parameter optimization
At this point I had two parameters to optimise: k and shrink_factor. I tweaked these with trial and error by submitting to AtCoder and waiting for the score to come through. AtCoder allows one submission every 5 minutes, so iteration time was a bit slow.
I got a new high score using k = 5.0 and a shrink_factor = 0%
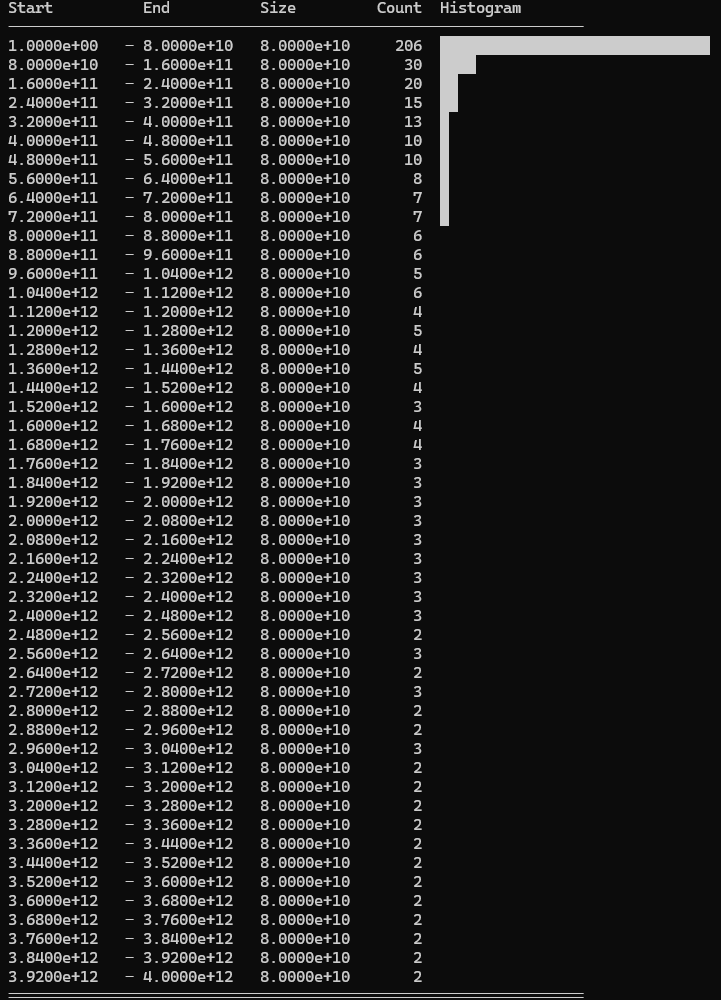
Selected values (excluding 50 hardcoded values): Exponential distribution (k=5.0)
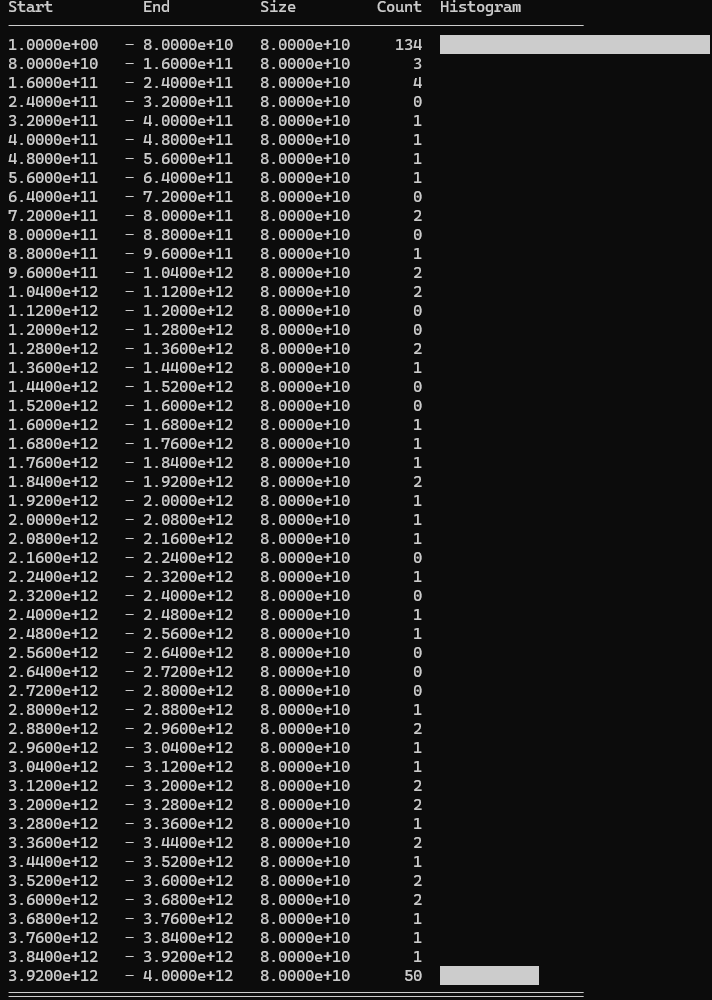
Used values: 236/500 cards used.
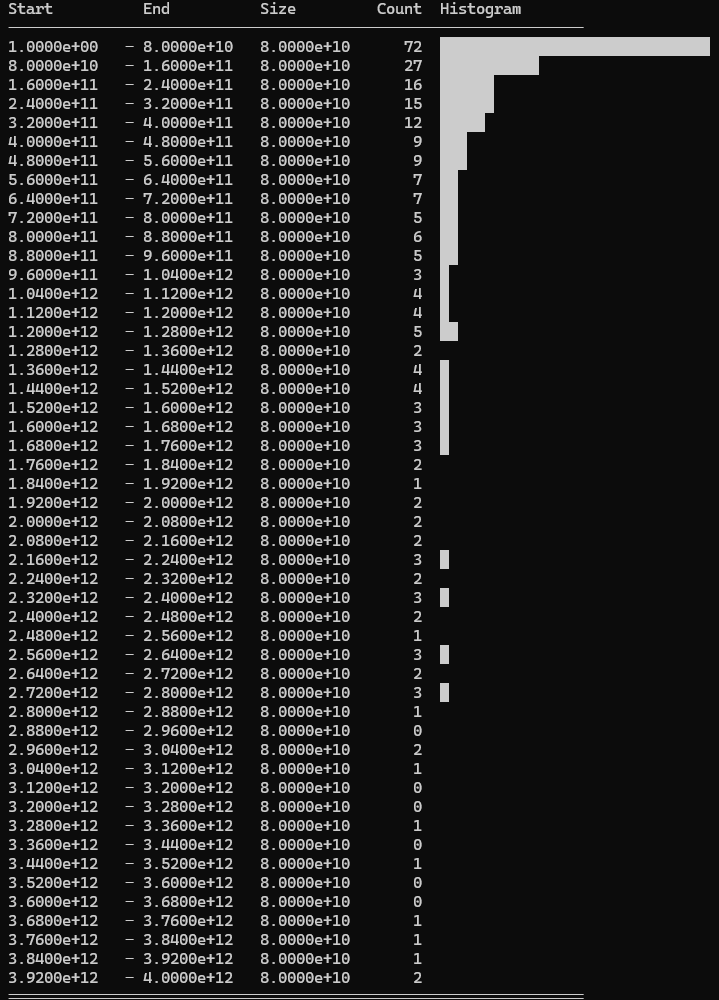
Discarded values: 264/500 cards discarded.
The distribution is heavily skewed to the lower end of the range, but not as extreme as the original logarithmic distribution. Around half the cards are discarded.
Score: 80.5M
3.6. Overfilling
Tuning the parameters involved a bit of downtime due to the 5 minute submission cooldown. In the meantime I improved the assignment in Phase 2.
I added another pass which runs after performing the initial greedy assignment. The second pass operates in a similar manner to the first pass, except it allows overshooting the target as long as it reduces the overall error. I probably should have done this from the start, but hacking it in as a second pass was quick and easy.
This made a marginal improvement to my score.
Score: 80.9M
3.7. More parameter tuning
I kept tuning the parameters, eventually landing on k = 10.0 and shrink_factor = 0.1%
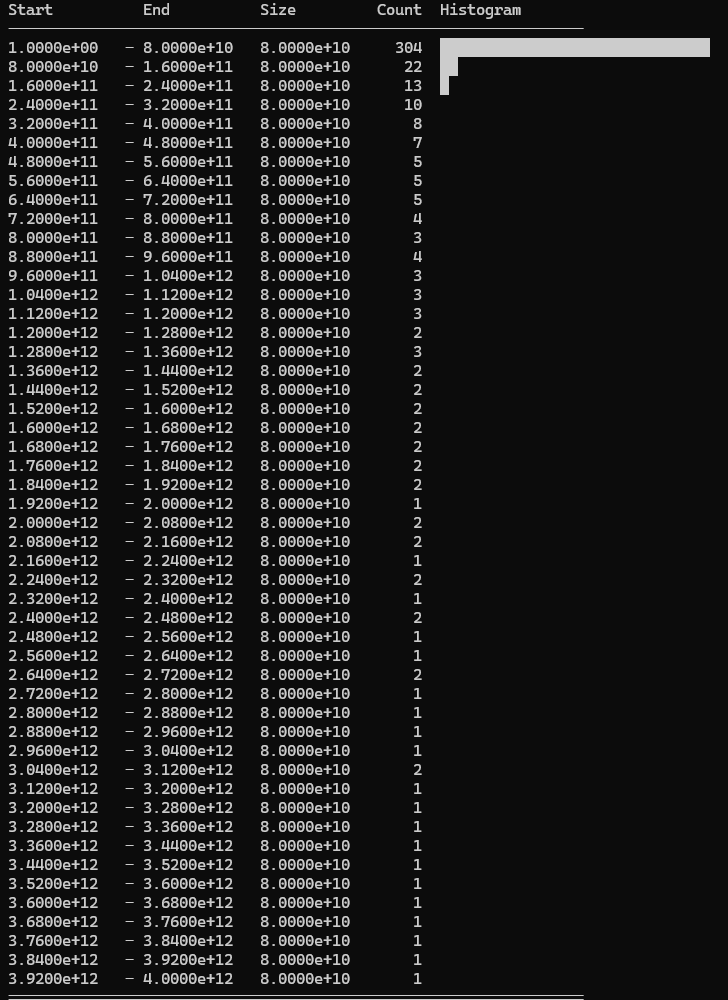
Selected values (excluding 50 hardcoded values): Exponential distribution (k=10.0)
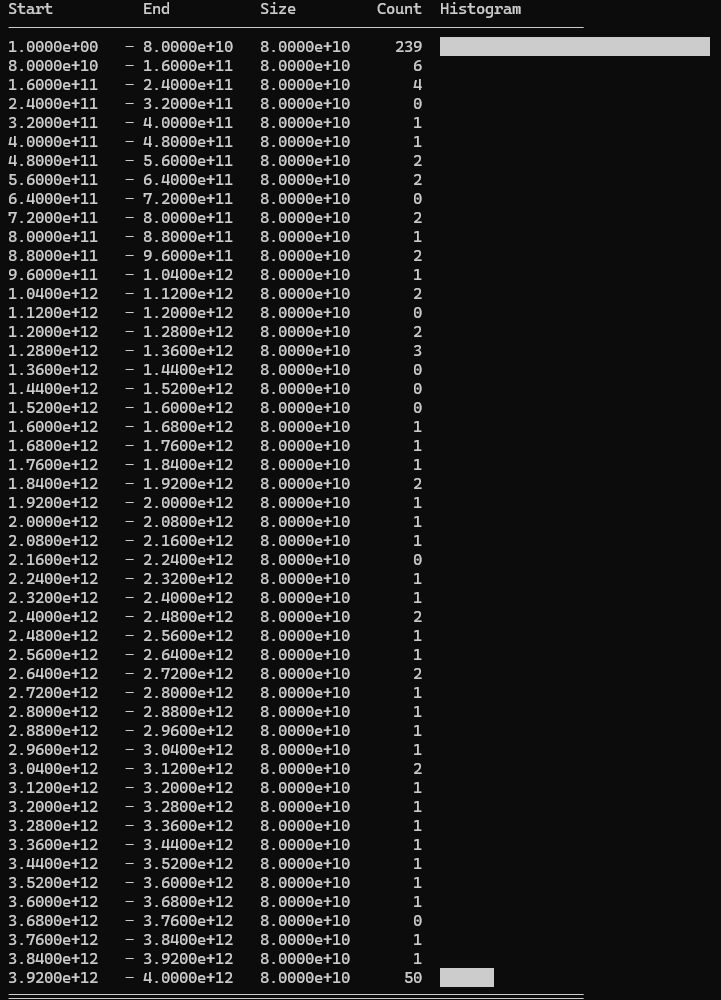
Used values: 349/500 cards used.
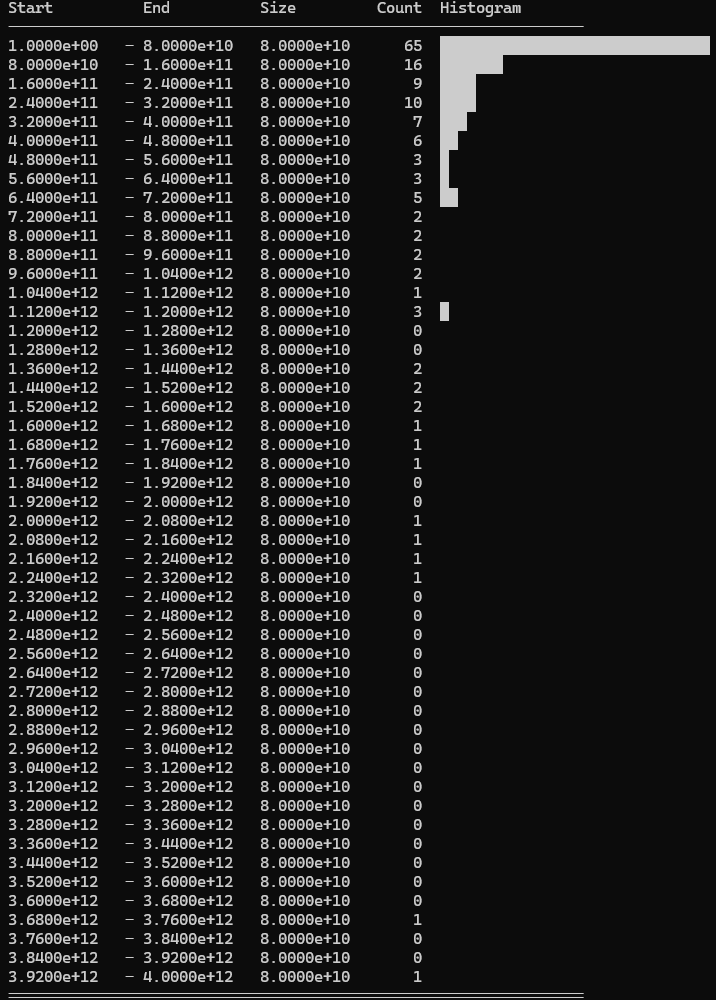
Discarded values: 151/500 cards discarded.
Values are even more skewed towards the lower end of the range. Only 151 cards are discarded, and very few of them are high value cards. This resulted in another reasonable score improvement.
Score: 87.6M
3.8. Card swapping
As the competition was coming to a close, I implemented some final improvements to the assignment phase. I added another series of passes which attempt to swap cards between piles to improve the overall score. The general idea is to swap cards from piles which are above their target to piles which are below their target.
The card swapping algorithm runs iteratively, examining every possible pair of piles in each round. For each pair, it identifies and executes the single best card swap that would reduce the overall error the most. The process continues until no beneficial swaps remain, or after 10 iterations.
This gave another marginal score improvement.
Score: 88.2M
4. Reflection
4.1. Generative AI Assistance
AtCoder permits and encourages the use of AI for Heuristic contests. It does however prohibit “pay to win” strategies which involve autonomously generating and evaluating many solutions. You can see the AI usage rules here. I think these rules are reasonable, and I heavily used Claude Code for my submission.
For the most part, I found Claude Code was very effective in allowing me to implement my ideas more quickly; I didn’t manually type out much code at all. In particular I found that I was able to quickly add visualisations and debug output. This was not only helpful, but made the competition more enjoyable. I didn’t use it much for actually coming up with the high level approach.
I’m finding AI coding assistants are particularly useful in competitions like this. They perform well in small codebases where there’s not a lot of external history or context you need to provide. I’m also using small visualisations much more since they’re so quick to implement, and perhaps more importantly, I don’t have to break my flow to go and build them myself.
4.2. Golang
I used Go for this competition because I’ve wanted to learn it for a while now. Due to heavy usage of Claude Code, I didn’t really feel like I learned much about Go at all… However I will say that Go’s simplicity basically removed any language barrier when it came to understanding and modifying the code.
4.3. Local Testing Infrastructure
I decided against building any local evaluation infrastructure for this competition. I felt like it was a more effective use of time to just submit to AtCoder to get feedback.
I’m not sure if this decision was the right call. I wasn’t able to optimise the k and shrink_factor parameters as much as I would have liked. The slow feedback loop also meant I was trying to task switch between parameter tuning and other code improvements.
I think building local testing infrastructure would have paid off. I could have whipped something up quickly with Claude Code as the problem statement describes exactly how test cases are generated.
This is also the sort of thing I need to get better at doing quickly for other competitions. Having a way to evaluate my code locally would enable automated parameter tuning, which would have been much more efficient than the manual trial-and-error approach I used.
5. Conclusion
Overall I’m happy with placing 153rd and with the approach I took to iteratively improve my solution. There are a lot of algorithmic and mathematical tools I’m missing, but that’s something I can work on in longer competitions.
For other writeups on this competition, check out https://atcoder.jp/contests/ahc053/editorial. Note that most of them are in the Japanese language section.
You might expect a score of 0 here since we’re discarding all cards, but you could actually get a worse result by assigning the maximum value (10¹⁵) to all 500 cards and not discarding any of them. This would create massive overshoots when trying to assign cards to targets. ↩︎
Comments
Thanks for reading! Feel free to leave a comment below, comments are linked directly to this GitHub discussion, so you can comment there directly if you prefer.